
Thủ Thuật về What do you call the characteristics or attributes of a sample that changes for individuals? Chi Tiết
Bạn đang tìm kiếm từ khóa What do you call the characteristics or attributes of a sample that changes for individuals? được Cập Nhật vào lúc : 2022-10-18 01:35:17 . Với phương châm chia sẻ Kinh Nghiệm về trong nội dung bài viết một cách Chi Tiết Mới Nhất. Nếu sau khi đọc tài liệu vẫn ko hiểu thì hoàn toàn có thể lại Comments ở cuối bài để Tác giả lý giải và hướng dẫn lại nha.Nội dung chính
- 1. These are attributes or characteristics that can have more than one value, such as height or weight. 2. These are variables that depend on other factors that are measured.3. It is a Latin research terminology which means "for example".4. It is a part or subset of population selected to participate in the research study.5. It involves the use of a variety of different graphical techniques.6. These are the devices/ instruments used to collect data such as questionnaire or computer-assistedinterviewing system.7. These are restrictions in a study that may decrease the credibility and generalizability of the research findings.8. It is a subject or issue that a researcher is interested in when conducting a research.9. It is the question around which a researcher centers his/her research.10. It is a list of all the sources used in the process of researching.
- Population vs Sample
- Subpopulations can Improve Your Analysis
- Parameter vs Statistic
- Representative Sampling and Simple Random Samples
- Example of a Population with Important Subpopulations
- What are characteristics of a sample called?
- What is a characteristic of an individual in statistics?
- What is the term for a characteristic or attribute that can assume different values?
- What are the characteristics of the individuals of the population being studied called?
1. These are attributes or characteristics that can have more than one value, such as height or weight. 2. These are variables that depend on other factors that are measured.3. It is a Latin research terminology which means "for example".4. It is a part or subset of population selected to participate in the research study.5. It involves the use of a variety of different graphical techniques.6. These are the devices/ instruments used to collect data such as questionnaire or computer-assistedinterviewing system.7. These are restrictions in a study that may decrease the credibility and generalizability of the research findings.8. It is a subject or issue that a researcher is interested in when conducting a research.9. It is the question around which a researcher centers his/her research.10. It is a list of all the sources used in the process of researching.
Inferential statistics lets you draw conclusions about populations by using small samples. Consequently, inferential statistics provide enormous benefits because typically you can’t measure an
entire population.
However, to gain these benefits, you must understand the relationship between populations, subpopulations, population parameters, samples, and sample statistics.
In this blog post, learn the differences between population vs. sample, parameter vs. statistic, and how to obtain representative samples using random sampling.
Related post:
Difference between Descriptive and Inferential Statistics
Populations can include people, but other examples include objects, events, businesses, and so on. In statistics, there are two general types of populations.
Populations can be the complete set of all similar items that exist. For example, the population of a country includes all people currently within that country. It’s a finite but potentially large list of members.
However, a population can be a theoretical construct that is potentially infinite in size. For example, quality improvement analysts often consider all current and future output from a manufacturing line to be part of a population.
Populations share a set of attributes that you define. For example, the following are populations:
- Stars in the Milky Way galaxy.
- Parts from a production line.
- Citizens of the United States.
Before you begin a study, you must carefully define the population that you are studying. These populations can be narrowly defined to meet the needs of your analysis. For example, adult Swedish women who are otherwise healthy but have osteoporosis.
Population vs Sample
It’s virtually impossible to measure a whole population completely because they tend to be extremely large. Consequently, researchers must measure a subset of the population for their study. These subsets are known as samples.
Typically, a researcher’s goal is to draw a representative sample from their target population. A representative sample mirrors the properties of the population. Using this approach, researchers can generalize the results from their sample to the population. Performing valid inferential statistics requires a strong relationship between the population and a sample.
In a later section, you’ll learn about the importance of representative samples and how to obtain them.
A statistical inference is when you use a sample to infer the properties of the entire population from which it was drawn. Learn more about making Statistical Inferences.
Subpopulations can Improve Your Analysis
Subpopulations share additional attributes. For instance, the population of the United States contains the subpopulations of men and women. You can also subdivide it in other ways such as region, age, socioeconomic status, and so on. Different studies that involve the same population can divide it into different subpopulations depending on what makes sense for the data and the analyses.
Understanding the subpopulations in your study helps you grasp the subject matter more thoroughly. They can also help you produce statistical models that fit the data better. Subpopulations are particularly important when they have characteristics that are systematically different than the overall population. When you analyze your data, you need to be aware of these deeper divisions. In fact, you can treat the relevant subpopulations as additional factors in later analyses.
For example, if you’re analyzing the average height of adults in the United States, you’ll improve your results by including male and female subpopulations because their heights are systematically different. I’ll cover that example in depth later in this post!
Parameter vs Statistic
A parameter is a value that describes a characteristic of an entire population, such as the population mean. Because you can almost never measure an entire population, you usually don’t know the real value of a parameter. In fact, parameter values are nearly always unknowable. While we don’t know the value, it definitely exists.
For example, the average height of adult women in the United States is a parameter that has an exact value—we just don’t know what it is!
The population mean and standard deviation are two common parameters. In statistics, Greek symbols usually represent population parameters, such as μ (mu) for the mean and σ (sigma) for the standard deviation.
A statistic is a characteristic of a sample. If you collect a sample and calculate the mean and standard deviation, these are sample statistics. Inferential statistics allow you to use sample statistics to make conclusions about a population. However, to draw valid conclusions, you must use particular sampling techniques. These techniques help ensure that samples produce unbiased estimates. Biased estimates are systematically too high or too low. You want unbiased estimates because they are correct on average.
In inferential statistics, we use sample statistics to estimate population parameters. For example, if we collect a random sample of adult women in the United States and measure their heights, we can calculate the sample mean and use it as an unbiased estimate of the population mean. We can also perform hypothesis testing on the sample estimate and create confidence intervals to construct a range that the actual population value likely falls within. Learn more about Parameters vs Statistics.
The law of large numbers states that as the sample size grows, sample statistics will converge on the population parameters. Additionally, the standard error of the mean mathematically describes how larger samples produce more precise estimates.
Related posts: Measures of Central Tendency and Measures of Variability
Representative Sampling and Simple Random Samples
 A sample is a subset of the whole population
A sample is a subset of the whole populationIn statistics, sampling refers to selecting a subset of a population. After drawing the sample, you measure one or more characteristics of all items in the sample, such as height, income, temperature, opinion, etc. If you want to draw conclusions about these characteristics in the whole population, it imposes restrictions on how you collect the sample. If you use an incorrect methodology, the sample might not represent the population, which can lead you to erroneous conclusions. Learn more about Representative Samples.
The most well-known method to obtain an unbiased, representative sample is simple random sampling. With this method, all items in the population have an equal probability of being selected. This process helps ensure that the sample includes the full range of the population. Additionally, all relevant subpopulations should be incorporated into the sample and represented accurately on average. Simple random sampling minimizes the bias and simplifies data analysis.
I’ll discuss sampling methodology in more detail in a future blog post, but there are several crucial caveats about simple random sampling. While this approach minimizes bias, it does not indicate that your sample statistics exactly equal the population parameters. Instead, estimates from a specific sample are likely to be a bit high or low, but the process produces accurate estimates on average. Furthermore, it is possible to obtain unusual samples with random sampling—it’s just not the expected result.
Methods for collecting a representative sample include the following:
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Systematic sampling
Additionally, random sampling might sound a bit haphazard and easy to do—both of which are not true. Simple random sampling assumes that you systematically compile a complete list of all people or items that exist in the population. You then randomly select subjects from that list and include them in the sample. It can be a very cumbersome process.
Random sampling can increase the internal and external validity of your study. Learn more about internal and external validity.
Conversely, convenience sampling does not tend to obtain representative samples. These samples are much easier to collect but the results are minimally useful.
Let’s bring these concepts to life!
Related post: Sample Statistics Are Always Wrong (to Some Extent)!
Example of a Population with Important Subpopulations
Suppose we’re studying the height of American citizens and let’s further assume that we don’t know much about the subject. Consequently, we collect a random sample, measure the heights in centimeters, and calculate the sample mean and standard deviation. Here is the CSV data file: Heights.
We obtain the following results:
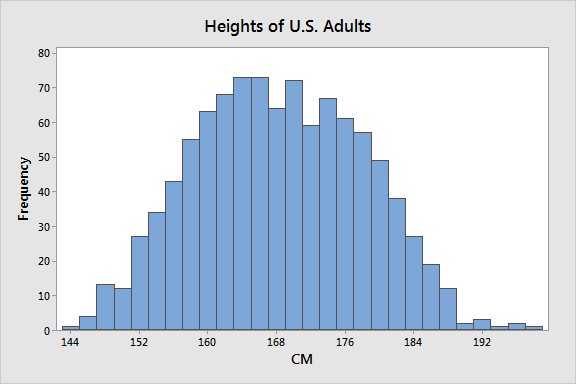

Because we gathered a random sample, we can assume that these sample statistics are unbiased estimates of the population parameters.
Now, suppose we learn more about the study area and include male and female as subpopulations. We obtain the following results.


Notice how the single broad distribution has been replaced by two narrower distributions? The distribution for each gender has a smaller standard deviation than the single distribution for all adults, which is consistent with the tighter spread around the means for both men and women in the graph. These results show how the mean provides more precise estimates when we assess heights by gender. In fact, the mean for the entire population does not equal the mean for either subpopulation. It’s misleading!
During this process, we learn that gender is a crucial subpopulation that relates to height and increases our understanding of the subject matter. In future studies about height, we can include gender as a predictor variable.
This example uses a categorical grouping variable (Gender) and a continuous outcome variable (Heights). When you want to compare distributions of continuous values between groups like this example, consider using boxplots and individual value plots. These plots become more useful as the number of groups increases.
This example is intentionally easy to understand but imagine a study about a less obvious subject. This process helps you gain new insights and produce better statistical models.
Using your knowledge of populations, subpopulations, parameters, sampling, and sample statistics, you can draw valuable conclusions about large populations by using small samples. For more information about how you can test hypotheses about populations, read my Overview of Hypothesis Tests.
When you take measurements, ensure that your measurement instruments and test scores are valid. To learn more, read my post Validity.
What are characteristics of a sample called?
A statistic is a characteristic of a sample.What is a characteristic of an individual in statistics?
* Statistical results should be interpreted by one who understands the methods used as well as the subject matter. Individuals and Variables. Individuals are the people or objects included in the study. A variable is the characteristic of the individual to be measured or observed.What is the term for a characteristic or attribute that can assume different values?
A variable is a characteristic that can be measured and that can assume different values. Height, age, income, province or country of birth, grades obtained school and type of housing are all examples of variables. Variables may be classified into two main categories: categorical and numeric.What are the characteristics of the individuals of the population being studied called?
Variables are the characteristics of the individuals in the population. Tải thêm tài liệu liên quan đến nội dung bài viết What do you call the characteristics or attributes of a sample that changes for individuals? Type of sampling Types of variables Number of variables Reply
Reply
 5
5
 0
0
 Chia sẻ
Chia sẻ
Chia Sẻ Link Download What do you call the characteristics or attributes of a sample that changes for individuals? miễn phí
Bạn vừa tìm hiểu thêm nội dung bài viết Với Một số hướng dẫn một cách rõ ràng hơn về Video What do you call the characteristics or attributes of a sample that changes for individuals? tiên tiến và phát triển nhất và ShareLink Tải What do you call the characteristics or attributes of a sample that changes for individuals? miễn phí.